Executive Summary
To address increasing data quality governance needs across heterogeneous data sources, we built a scalable, cloud-native data quality platform—enhanced with intelligent agents—to deliver automated data quality checks, reporting, and observability. Leveraging Amazon EKS, Amazon RDS, and Amazon Bedrock, the system integrates self-scheduled jobs, modular rule definitions, and intelligent agents (Check Creation and Reporting) to maintain data trust and compliance. The solution reduced manual validation efforts by 65% and increased anomaly detection accuracy by 30%.
Customer Challenge
Business Challenges
Customer, a mid-to-large-scale enterprise managing mission-critical operational data across multiple business units, faced significant challenges in maintaining consistent and trustworthy data across its systems. The organisation relied on disparate data sources—including PostgreSQL, Snowflake, Redshift, and Spark—without a centralised mechanism to monitor, validate, or report on data quality. This fragmentation led to blind spots in data lineage, broken pipelines, and inconsistencies in downstream analytics.
Business users were burdened with manual, error-prone processes to define and execute quality checks. These checks were often embedded in hardcoded scripts or BI tool logic, which made them unscalable, difficult to audit, and disconnected from source systems. As data volumes grew, the organization saw increased data-related incidents—ranging from incorrect report generation to non-compliant usage of sensitive fields—leading to lost productivity and reduced trust in business insights.
Additionally, the lack of automated reporting and transparency into data quality meant business teams were unaware of data issues until after decisions had been made. These delayed resolution cycles disrupted critical operations and exposed the organisation to compliance risks.
Customer’s strategic business objectives included:
-
Unifying data quality governance across departments and systems
-
Reducing manual effort for defining and enforcing quality checks
-
Accelerating insight generation with reliable, high-quality data
With business expansion plans underway and data complexity growing exponentially, there was immediate pressure to adopt an intelligent, agent-driven, cloud-native solution that could deliver continuous data quality observability and empower both technical and business stakeholders.
Technical Challenges
The customer’s fragmented and legacy-oriented data environment posed significant technical hurdles in establishing a unified, scalable, intelligent data quality platform. The architecture was composed of multiple siloed systems, including legacy RDS databases, monolithic ETL workflows, and disparate rule enforcement mechanisms. These components operated independently, making it difficult to orchestrate end-to-end data validation processes or ensure consistent pipeline rule enforcement.
The lack of a centralised metadata layer, schema registry, or data lineage framework hindered root cause analysis and traceability of quality issues. With data flowing through multiple unmonitored transformation layers, errors often surfaced downstream without clear visibility into their origin. Manual logging and script-based rule execution increased the operational burden and introduced the risk of silent failures.
Integration challenges further compounded the issue. The platform needed to interact with a wide range of data sources—PostgreSQL, Spark, Redshift, BigQuery, and more—each with unique metadata formats and connectivity constraints. The legacy tools in place lacked the extensibility and cloud-native APIs required to support modern agent orchestration or multi-source rule propagation.
Performance bottlenecks were frequent during large-scale data scans or validations, particularly in scenarios involving recursive quality checks or downstream dependency evaluations. This affected SLAs and degraded trust in the data platform’s reliability.
The prior setup made it difficult to meet security and compliance requirements, including end-to-end encryption, fine-grained IAM-based access, and auditable rule execution. There was also no mechanism to ensure reproducibility or explainability of quality decisions, an increasingly critical requirement in regulated environments.
To overcome these barriers, a complete technical re-architecture was needed, centred around container-native services, declarative rule orchestration, and LLM-powered agents deployed securely on AWS using services like Amazon EKS, Bedrock, and S3.

Partner Solution
Solution Overview
Xenonstack implemented a modular, agent-driven data quality governance solution built on a cloud-native architecture, specifically designed to address the scalability, integration, and compliance needs of the Customer’s operational data landscape. The solution was deployed on Amazon EKS, enabling containerised orchestration of the core Data Quality Engine, Check Creation Agent, and Reporting Agent. This setup provided an intelligent control plane for continuous rule execution, anomaly detection, and quality reporting across heterogeneous data sources.
The architecture was designed with decoupled layers—supporting ingestion, rule definition, validation, and reporting—allowing each component to scale independently. Modular rule templates (Python and Jinja2-based) were stored centrally and version-controlled, enabling reusable and auditable logic. Quality check execution was fully automated, leveraging cron-based scheduling and event-driven triggers. The agents, powered by LLM inference from Amazon Bedrock, enabled dynamic rule generation and contextual reporting explanations.
Amazon RDS, S3, and other source systems were integrated through a secure, policy-driven data access framework using IAM roles and VPC endpoints. Deployment automation was managed via GitOps-style CI/CD pipelines with dev, staging, and prod environment overlays. Observability was embedded through Amazon CloudWatch and QuickSight, offering real-time insights into rule performance, data health, and agent activity.
The result was a unified and extensible platform that empowered technical and business teams to define, monitor, and act on data quality metrics, supporting faster decision-making, higher trust, and better regulatory compliance.
AWS Services Used
-
Amazon EKS: Hosts the Data Quality Core and Orchestrator Agent in Kubernetes.
-
Amazon S3: Serves as the Data Quality Lake and archive for rule results.
-
Amazon RDS: Stores warehouse-based Data Quality Check metadata.
-
Amazon QuickSight: Generates embedded dashboards and visual reports.
-
Amazon Bedrock: Provides model inference capabilities for the agents.
-
Amazon VPC: Ensures secure inter-service communication.
Architecture Diagram 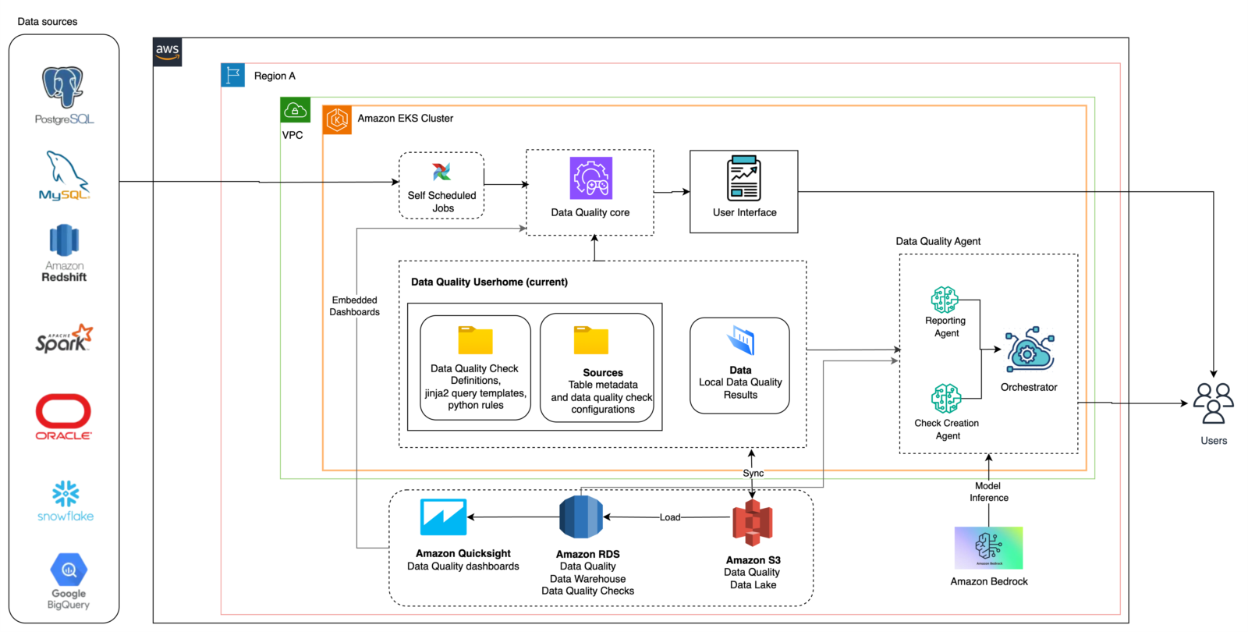
Implementation Details
The implementation followed an Agile, sprint-based delivery model executed over a 10-month period, involving iterative development, integration testing, and stakeholder validation. The project kicked off with joint discovery sessions involving data stewards, compliance teams, and engineering leads to identify business-critical datasets, validation pain points, and compliance obligations such as auditability, lineage traceability, and data sovereignty.
Core components of the platform—including the Data Quality Engine, Orchestrator, and LLM-powered Check Creation and Reporting Agents—were containerized and deployed on Amazon EKS using Helm charts with environment-specific overlays for development, staging, and production. These agents interfaced with a modular rules library written in Python and Jinja2, centrally stored and version-controlled in Git.
Integration pipelines were established to connect diverse data sources—PostgreSQL, Redshift, Snowflake, and Spark—using lightweight metadata adapters and secure VPC endpoints. Amazon RDS was used to maintain rule execution metadata and history, while Amazon S3 served as the persistent quality result lake.
Amazon Bedrock was integrated during mid-phase development to enable intelligent agentic capabilities, including automated rule recommendations and natural language-based reporting summaries. This empowered business users to interact with the system with minimal technical overhead.
Timeline and Major Milestones:
-
Months 1–2: Requirement workshops, Kubernetes cluster setup
-
Months 3–4: Rule template design, data source integration, Amazon RDS and S3 configuration
-
Month 5: Agent containerization and orchestrator deployment on EKS
-
Months 6–7: Bedrock integration for LLM-based rule assistance and summary reporting
-
Months 8–9: QuickSight dashboarding and monitoring
-
Month 10: Final compliance validation, user training, and full production rollout
Innovation and Best Practices
The solution was designed in alignment with the AWS Well-Architected Framework, with a strong focus on security, reliability, and operational excellence. Xenonstack adopted a container-native approach, deploying loosely coupled agents and services on Amazon EKS to ensure fault isolation, horizontal scalability, and low operational overhead. All infrastructure components were provisioned and managed using Infrastructure as Code (IaC) with Helm and Terraform, enabling repeatable, auditable deployments across environments.
A key innovation was the implementation of LLM-powered agents—Check Creation Agent and Reporting Agent—integrated with Amazon Bedrock. These agents enabled intelligent automation of rule generation, anomaly summarization, and business-readable reporting, reducing the manual effort traditionally required for data quality governance.
The modular rule engine, built using Python and Jinja2 templates, supported declarative logic that could be reused across multiple pipelines. This allowed rule definitions to evolve independently of the underlying data sources or transformation logic. A GitOps pipeline ensures that rule updates can be safely reviewed, versioned, and deployed through CI/CD workflows.
Bedrock’s model orchestration provided explainability and transparency within the agent outputs, ensuring that rule violations were flagged and contextually explained in natural language—empowering business users and reducing resolution times.
The architecture embedded observability through centralised logging (Amazon CloudWatch), quality dashboards (Amazon QuickSight), and performance tracing, enabling proactive monitoring and continuous optimisation. These innovations collectively elevated the platform from a static data validation tool to a dynamic, intelligent governance layer adaptable to changing data landscapes.

Results and Benefits
Business Outcomes and Success Metrics
-
Reduced manual rule enforcement effort by 65%.
-
Boosted data pipeline reliability with 30% higher anomaly detection accuracy.
-
Real-time quality reporting improves stakeholder trust.
-
Embedded dashboards help align data owners and engineers.
-
Achieved operational visibility for 100+ pipelines across 7 data sources.
Technical Benefits
-
High scalability via EKS and stateless architecture.
-
Fault-tolerant data quality agents orchestrated with Bedrock-enhanced logic.
-
Reusable modular rules enable CI/CD and rule versioning.
-
Reduced operational overhead through autonomous job scheduling.
Customer Testimonial
“The agentic data quality architecture has completely transformed how we manage data reliability. What took hours of manual effort is now automated, auditable, and intelligent—thanks to the LLM-powered check and reporting agents.”
— Lead Data Platform Engineer

Lessons Learned
Challenges Overcome
-
Harmonizing multiple schema types across source systems.
-
Scaling LLM inference securely inside EKS using Bedrock.
-
Orchestrating agent flows without manual intervention.
Best Practices Identified
- Build agents as stateless microservices for better scaling.
- Store all rule definitions with version control and template support.
- Use Bedrock for explainability, not just automation.
- Integrate dashboarding early to measure real-time impact.
- Keep orchestration logic decoupled from rule logic for maintainability
Future’s Plans
-
Expand Check Agent to support anomaly detection via time-series ML.
-
Introduce Data Remediation Agent for auto-fixable issues.
-
Add a chat interface using Amazon Lex + Bedrock for interactive rule testing.
-
Push Data Quality SLA alerts into business observability systems (PagerDuty, Opsgenie).
-
Broaden support for unstructured and semi-structured data validations.

























